[1] kogpt2 기반 심리 케어 챗봇
한줄 설명
KoGPT2 모델은 문장을 "생성"해내는 모델입니다.
심리 케어 목적의 챗봇을 구현하기 위해 입력 받은 내용에 대해 위로하거나 공감하거나 부드러운 표현으로 반응하고 문장을 생성해내도록 파인 튜닝을 진행했습니다.
학습 코드 링크입니다.
사용한 데이터셋
1. ai hub 제공, 웰니스 대화 스크립트 데이터셋
AI hub > 외부데이터 > KETI R&D데이터 >인식기술(언어지능) > 웰니스 대화 스크립트 데이터셋
2. @songys (송영숙님) 제공, 챗봇 데이터셋
두 데이터를 아래의 데이터 형식에 맞게 가공했습니다.
학습 환경
colab 기본 환경에서도 가능합니다만, 시간이 꽤 오래걸리는 편입니다!
1 epoch에 15~16분 정도 걸리는데 epoch 최대 5번 정도까지가 적정선이라고 생각해서 런타임이 끊어지지만 않으면 충분히 가능합니다.
저는 학교에서 지원받은 gpu 서버에서 학습시켰습니다.
라이브러리 설치
사실 학습시킬 때 의존성 문제를 해결하는 것이 가장 크기 때문에 제가 학습시켰던 환경에 대해서 자세히 적어두겠습니다.
linux 환경에서 (더 자세히는 ubuntu)
저는 python 버전이 3.8.10 입니다.
requirements_linux.txt 에 필요한 의존성을 작성해두었습니다.
transformers==4.5.1
pytorch_lightning==1.2.10
pandas설치합니다. 아래의 명령어로 실행시킬 수 있습니다.
pip install -r requirements_linux.txt아래의 명령어로 torch의 버전으로 재설치해주시면 됩니다.
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.htmlgraphic card(nvidia 같은, 저는_RTX 3080)가 지원하는 torch 버전이 몇 개 없어서 구글링해보면 애를 먹고 있는 사람들이 굉장히 많다.
capability sm_86 is not compatible
The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_70 sm_75
이런 문구들을 심심찮게 볼 수 있다.
https://pytorch.org/get-started/previous-versions/
pytorch 공식 사이트이고 이전 버전 설치 명령어를 자세히 기록해둔 링크이다.
호환이 되는 torch를 찾을 때까지 일없이 설치해보고 실행해보면 된다.
cuda 버전이 안맞아도 일단 시도해보는 것이 좋다..!
코드 설명
레퍼런스 링크입니다.
저는 심리 케어 목적에 맞추어 가공한 데이터와 조금씩 수정해 학습시켰던 코드를 저장하기 위해 github repo를 생성해 저장해두었습니다.
제 레포의 trainer_s.py 코드에 대해 설명해드리겠습니다.
import argparse
import logging
import numpy as np
import pandas as pd
import torch
from pytorch_lightning import Trainer
from pytorch_lightning.callbacks import ModelCheckpoint
from pytorch_lightning.core.lightning import LightningModule
from torch.utils.data import DataLoader, Dataset
from transformers.optimization import AdamW, get_cosine_schedule_with_warmup
from transformers import PreTrainedTokenizerFast, GPT2LMHeadModelpytorch lightning을 활용해 구현되었습니다.
parser = argparse.ArgumentParser(description='Simsimi based on KoGPT-2')
parser.add_argument('--chat',
action='store_true',
default=False,
help='response generation on given user input')
parser.add_argument('--sentiment',
type=str,
default='0',
help='sentiment for system. 0 is neutral, 1 is negative, 2 is positive.')
parser.add_argument('--model_params',
type=str,
default='model_chp/model_-last.ckpt',
help='model binary for starting chat')
parser.add_argument('--train',
action='store_true',
default=False,
help='for training')ArgumentParser는 커맨드 라인에서 프로그램을 실행할 때 인수를 받아 처리할 수 있도록 도와하는 표준 라이브러리입니다.
python trainer_s.py --train
학습을 시작하기 위해서는 commend line에서 --train 옵션을 주어 실행해야 합니다.
python trainer_s.py --chat
명령으로 채팅할 수 있습니다.
logger = logging.getLogger()
logger.setLevel(logging.INFO)Python에서 기본적으로 제공하는 logging 모듈을 사용해 로그를 출력하기 위해 불러옵니다.
INFO level로 설정해 작업이 정상적으로 작동하고 있다는 확인 메시지도 보여달라고 설정했습니다.
로그가 길게 뜨는 게 싫다면 이 부분을 지워주시거나 로거 level을 조절해주시면 됩니다.
U_TKN = '<usr>'
S_TKN = '<sys>'
BOS = '</s>'
EOS = '</s>'
MASK = '<unused0>'
SENT = '<unused1>'
PAD = '<pad>'
TOKENIZER = PreTrainedTokenizerFast.from_pretrained("skt/kogpt2-base-v2",
bos_token=BOS, eos_token=EOS, unk_token='<unk>',
pad_token=PAD, mask_token=MASK)
설정하고 싶은 토큰을 상수로 설정하고 hugging face에 올라와있는 skt/kogpt2-base-v2 버전의 토크나이저를 다운로드합니다.
PreTrainedTokenizerFast 의 속성값은 hugging face의 공식 문서에서 확인할 수 있습니다.
class CharDataset(Dataset):
def __init__(self, chats, max_len=32):
self._data = chats
self.first = True
self.q_token = U_TKN
self.a_token = S_TKN
self.sent_token = SENT
self.bos = BOS
self.eos = EOS
self.mask = MASK
self.pad = PAD
self.max_len = max_len
self.tokenizer = TOKENIZER
def __len__(self):
return len(self._data)
def __getitem__(self, idx):
turn = self._data.iloc[idx]
q = turn['Q']
a = turn['A']
sentiment = str(turn['label'])
q_toked = self.tokenizer.tokenize(self.q_token + q + \
self.sent_token + sentiment)
q_len = len(q_toked)
a_toked = self.tokenizer.tokenize(self.a_token + a + self.eos)
a_len = len(a_toked)
if q_len + a_len > self.max_len:
a_len = self.max_len - q_len
if a_len <= 0:
q_toked = q_toked[-(int(self.max_len/2)):]
q_len = len(q_toked)
a_len = self.max_len - q_len
assert a_len > 0
a_toked = a_toked[:a_len]
a_len = len(a_toked)
assert a_len == len(a_toked), f'{a_len} ==? {len(a_toked)}'
# [mask, mask, ...., mask, ..., <bos>,..A.. <eos>, <pad>....]
labels = [
self.mask,
] * q_len + a_toked[1:]
if self.first:
logging.info("contexts : {}".format(q))
logging.info("toked ctx: {}".format(q_toked))
logging.info("response : {}".format(a))
logging.info("toked response : {}".format(a_toked))
logging.info('labels {}'.format(labels))
self.first = False
mask = [0] * q_len + [1] * a_len + [0] * (self.max_len - q_len - a_len)
self.max_len
labels_ids = self.tokenizer.convert_tokens_to_ids(labels)
while len(labels_ids) < self.max_len:
labels_ids += [self.tokenizer.pad_token_id]
token_ids = self.tokenizer.convert_tokens_to_ids(q_toked + a_toked)
while len(token_ids) < self.max_len:
token_ids += [self.tokenizer.pad_token_id]
return(token_ids, np.array(mask),
labels_ids)CharDataset은 Dataset을 상속받았으므로 init, len, getitem 메서드를 오버라이딩해야합니다.
Dataset은 torch.utils.data.Dataset 에 위치해 있는 데이터셋을 나타내는 추상클래스입니다.
len은 데이터셋의 크기를 리턴하고 getitem은 i번째 샘플을 찾는데 사용합니다.
class KoGPT2Chat(LightningModule):
def __init__(self, hparams, **kwargs):
super(KoGPT2Chat, self).__init__()
self.hparams = hparams
self.neg = -1e18
self.kogpt2 = GPT2LMHeadModel.from_pretrained('skt/kogpt2-base-v2')
self.loss_function = torch.nn.CrossEntropyLoss(reduction='none')
@staticmethod
def add_model_specific_args(parent_parser):
# add model specific args
parser = argparse.ArgumentParser(parents=[parent_parser], add_help=False)
parser.add_argument('--max-len',
type=int,
default=64,
help='max sentence length on input (default: 32)')
parser.add_argument('--batch-size',
type=int,
default=96,
help='batch size for training (default: 96)')
parser.add_argument('--lr',
type=float,
default=5e-5,
help='The initial learning rate')
parser.add_argument('--warmup_ratio',
type=float,
default=0.1,
help='warmup ratio')
return parser
def forward(self, inputs):
# (batch, seq_len, hiddens)
output = self.kogpt2(inputs, return_dict=True)
return output.logits
def training_step(self, batch, batch_idx):
token_ids, mask, label = batch
out = self(token_ids)
mask_3d = mask.unsqueeze(dim=2).repeat_interleave(repeats=out.shape[2], dim=2)
mask_out = torch.where(mask_3d == 1, out, self.neg * torch.ones_like(out))
loss = self.loss_function(mask_out.transpose(2, 1), label)
loss_avg = loss.sum() / mask.sum()
self.log('train_loss', loss_avg)
return loss_avg
def configure_optimizers(self):
# Prepare optimizer
param_optimizer = list(self.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters,
lr=self.hparams.lr, correct_bias=False)
# warm up lr
num_train_steps = len(self.train_dataloader()) * self.hparams.max_epochs
num_warmup_steps = int(num_train_steps * self.hparams.warmup_ratio)
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=num_warmup_steps, num_training_steps=num_train_steps)
lr_scheduler = {'scheduler': scheduler, 'name': 'cosine_schedule_with_warmup',
'monitor': 'loss', 'interval': 'step',
'frequency': 1}
return [optimizer], [lr_scheduler]
def _collate_fn(self, batch):
data = [item[0] for item in batch]
mask = [item[1] for item in batch]
label = [item[2] for item in batch]
return torch.LongTensor(data), torch.LongTensor(mask), torch.LongTensor(label)
def train_dataloader(self):
data = pd.read_csv('chatbot_dataset_s.csv')
self.train_set = CharDataset(data, max_len=self.hparams.max_len)
train_dataloader = DataLoader(
self.train_set, batch_size=self.hparams.batch_size, num_workers=2,
shuffle=True, collate_fn=self._collate_fn)
return train_dataloader
def chat(self, sent='0'):
tok = TOKENIZER
sent_tokens = tok.tokenize(sent)
with torch.no_grad():
p = input('user > ')
q = p.strip()
a = ''
while 1:
input_ids = torch.LongTensor(tok.encode(U_TKN + q + SENT + sent + S_TKN + a)).unsqueeze(dim=0)
pred = self(input_ids)
gen = tok.convert_ids_to_tokens(
torch.argmax(
pred,
dim=-1).squeeze().numpy().tolist())[-1]
if gen == EOS:
break
a += gen.replace('▁', ' ')
print("Chatbot > {}".format(a.strip()))
return qhyperparameter 들을 ArgumentParser를 사용해 커맨드 라인에서 옵션으로 지정해줄 수 있도록 설정합니다.
pytorch lightning에서는 trainer와 모델이 상호작용을 할 수 있도록 pytorch의 nn.Module의 상위 클래스인 LightningModule을 구현해야 합니다. LightningModule을 정의하기 위해 LightningModule 클래스를 상속받고 메소드를 오버라이딩하여 구현해야 합니다.
forward는 모델의 추론 결과를 제공하고 싶을 때 사용합니다. 꼭 정의해야 하는 메서드는 아닙니다. 하지만 self(입력)과 같이 사용할 수 있게 만들어주므로 구현해주면 편리합니다.
training_step과 configure_optimizers 필수적으로 구현해야 합니다.
training_step은 학습 루프의 body 부분을 나타냅니다. 이 메소드에서는 인자로 training dataloader가 제공하는 batch와 해당 batch의 index가 주어지고 train loss를 계산하여 반환합니다.
configure_optimizers에서는 모델의 최적 파라미터를 찾을 때 사용할 optimizer와 scheduler를 구현합니다. 이 코드에서는 학습해야 할 모델이 하나이므로 하나의 Adam optimzer만 사용합니다.
train_dataloader는 batch 기반으로 모델을 학습시키기 위해 데이터셋을 입력으로 받아 batch size로 슬라이싱하는 역할을 합니다.
DataLoader에는 batchsize를 포함하여 여러가지 파라미터들이 있는데, 이 중 하나가 바로 collate_fn입니다.
_collate_fn 함수로 커스텀 해준 것을 볼 수 있는데, 가변 길이의 input을 batch로 잘 묶어서 DataLoader로 넘겨주는 역할을 합니다.
chat 은 사용자가 입력을 하면 self(토큰화된 입력) 으로 forward가 실행되어 챗봇의 응답을 반환하는 함수입니다.
parser = KoGPT2Chat.add_model_specific_args(parser)
parser = Trainer.add_argparse_args(parser)
args = parser.parse_args()
logging.info(args)
if __name__ == "__main__":
# python trainer_s.py --train --gpus 1 --max_epochs 5
if args.train:
checkpoint_callback = ModelCheckpoint(
dirpath='model_chp',
filename='{epoch:02d}-{train_loss:.2f}',
verbose=True,
save_last=True,
monitor='train_loss',
mode='min',
prefix='model_'
)
model = KoGPT2Chat(args)
model.train()
trainer = Trainer.from_argparse_args(
args,
checkpoint_callback=checkpoint_callback, gradient_clip_val=1.0)
trainer.fit(model)
logging.info('best model path {}'.format(checkpoint_callback.best_model_path))
# python trainer_s.py --chat --gpus 1
if args.chat:
model = KoGPT2Chat.load_from_checkpoint(args.model_params)
model.chat()학습을 시키고 나서 아래와 같은 경로로 2개의 모델이 저장이 됩니다.
model_chp/model_-epoch=04-train_loss=16.33.ckpt
model_chp/model_-last.ckpt
첫번째 모델은 train_loss가 가장 작은 모델 파일이고,
두번째 파일은 지정한 epoch 수만큼 학습시키고 난 뒤 얻은 모델 파일입니다.
python trainer_s.py --chat 명령어로 입력에 대한 챗봇의 응답을 확인할 수 있습니다.
출력 결과
아래의 결과는 flask 웹 어플리케이션에 담아 실행해본 결과입니다.

1번부터 7번까지는 부정적인 입력이고 8번부터 10번까지는 긍정적인 입력에 대해 테스트한 결과입니다.
전반적으로 짧게 응답해줍니다. 주제에 벗어나는 응답도 있지만 이정도면 꽤 응답을 잘해주고 있는 것 같습니다.
실제로 사용해보면 밝은 분위기의 문장을 넣으면 웃긴 대답을 받을 때도 있습니다.
학습시킨 데이터셋과 다른 문장으로 대답하는 경우가 훨씬 많습니다. KoGPT2는 문장을 생성해내는 모델이라 당연한 이야기입니다.
[2] kobert 기반 심리 케어 챗봇
한줄 설명
kobert는 pretrain 되어 있는 기계번역 모델입니다.
kobert는 다중 분류에 많이 활용되고 있습니다.
kobert 기반 심리 케어 챗봇은 입력을 359가지의 특정 상황으로 분류한 다음, 해당 클래스에서 정해진 답변 중 하나를 랜덤으로 응답하는 방식으로 구현하였습니다.
학습 코드 링크입니다.
사용한 데이터셋

ai hub 제공, 웰니스 대화 스크립트 데이터셋
강남 세브란스에서 전달받은 상담데이터가 대화 의도에 따라 359개 상황으로 분류되어 있습니다.
AI hub > 외부데이터 > KETI R&D데이터 >인식기술(언어지능) > 웰니스 대화 스크립트 데이터셋
학습 환경
colab pro 환경이거나 gpu 서버에서 가능합니다.
클래스가 359가지 되기 때문에 epoch를 50번 이상으로 학습시켜줘야 합니다. 참고로 해당 hyper parameter는 경험적으로 얻은 수치입니다.
colab 기본 환경에서는


batch size를 1로 했을 때 1 epoch 당 16분 정도 소요됩니다. batch size를 2 이상으로 높이면 colab에서 RuntimeError: CUDA out of memory 라고 에러를 낼 것입니다. gpu ram이 부족한 것이죠. 사실상 어렵다고 볼 수 있습니다.
colab pro 환경에서는
batch size를 16 → 8 → 4 까지 줄였을 때 가능했고 1 epoch 당 3분 40~50초 정도 걸렸습니다.

RTX 3080 GPU 서버에서는
batch size를 16으로 설정해도 가능했고, 1 epoch 당 1분 50초 정도 걸렸습니다.

라이브러리 설치
colab에서는
!pip install kobert-transformers==0.4.1
!pip install transformers==3.0.2
!pip install torch
!pip install tokenizers==0.8.1rc1linux에서는
pip install kobert-transformers==0.4.1
pip install transformers==3.0.2
pip install tokenizers==0.8.1rc1
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html코드 설명
레퍼런스 링크입니다.
직접 학습시켜보면서 오류를 해결하여 수정한 부분이 생겨 github repo로 생성해 저장해두었습니다.
제 레포의 코드를 기준으로 설명해드리겠습니다.

한 파일 내에서 작성되지 않아 디렉터리 구조를 먼저 보여드리고 설명하겠습니다.
data 폴더 안에 있는 텍스트 파일은 간단한 전처리 코드를 거쳐 만들어진 파일입니다.

순서대로 category, answer, for_text_classification_all 파일의 내용입니다.
내용을 보면 감이 오실텐데요, 가장 오른쪽의 데이터를 학습시켜 몇 번 class에 속하는지 모델을 통해 분류하고
이후에는 분류된 class 번호로 category 정보와 answer로 챗봇이 응답합니다.
전처리 코드는 매우 간단하기 때문에 코드 링크로 연결해두겠습니다.
import torch
import torch.nn as nn
from kobert_transformers import get_kobert_model
from torch.nn import CrossEntropyLoss, MSELoss
from transformers import BertPreTrainedModel
from model.configuration import get_kobert_config
class KoBERTforSequenceClassfication(BertPreTrainedModel):
def __init__(self,
num_labels=359,
hidden_size=768,
hidden_dropout_prob=0.1,
):
super().__init__(get_kobert_config())
self.num_labels = num_labels
self.kobert = get_kobert_model()
self.dropout = nn.Dropout(hidden_dropout_prob)
self.classifier = nn.Linear(hidden_size, num_labels)
self.init_weights()
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
):
outputs = self.kobert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
outputs = (logits,) + outputs[2:] # add hidden states and attention if they are here
if labels is not None:
if self.num_labels == 1:
# We are doing regression
loss_fct = MSELoss()
loss = loss_fct(logits.view(-1), labels.view(-1))
else:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
outputs = (loss,) + outputs
return outputs # (loss), logits, (hidden_states), (attentions)다음은 model 폴더 안의 파일을 보겠습니다.
위 코드는 classifier.py 파일의 코드입니다.
이번 챗봇 모델은 kobert 모델을 사용해 먼저 어떤 상황인지 분류해야하는 것이 목적입니다.
그래서 classifier (분류기)가 필요합니다. 이 부분은 train 뿐만 아니라 test할 때에도 사용합니다.
import logging
from transformers import BertConfig
logger = logging.getLogger(__name__)
#KoBERT
kobert_config = {
'attention_probs_dropout_prob': 0.1,
'hidden_act': 'gelu',
'hidden_dropout_prob': 0.1,
'hidden_size': 768,
'initializer_range': 0.02,
'intermediate_size': 3072,
'max_position_embeddings': 512,
'num_attention_heads': 12,
'num_hidden_layers': 12,
'type_vocab_size': 2,
'vocab_size': 8002
}
def get_kobert_config():
return BertConfig.from_dict(kobert_config)configuration.py 의 코드입니다.
configuration.py 모델 구조 등의 설정값을 지정해둔 파일이고, classifier.py 코드에서 불러와 사용합니다.
import torch
from kobert_transformers import get_tokenizer
from torch.utils.data import Dataset
class WellnessTextClassificationDataset(Dataset):
def __init__(self,
file_path="./data/wellness_dialog_for_text_classification_all.txt",
num_label=359,
device='cpu',
max_seq_len=512, # KoBERT max_length
tokenizer=None
):
self.file_path = file_path
self.device = device
self.data = []
self.tokenizer = tokenizer if tokenizer is not None else get_tokenizer()
file = open(self.file_path, 'r', encoding='utf-8')
while True:
line = file.readline()
if not line:
break
datas = line.split(" ")
index_of_words = self.tokenizer.encode(datas[0])
token_type_ids = [0] * len(index_of_words)
attention_mask = [1] * len(index_of_words)
# Padding Length
padding_length = max_seq_len - len(index_of_words)
# Zero Padding
index_of_words += [0] * padding_length
token_type_ids += [0] * padding_length
attention_mask += [0] * padding_length
# Label
label = int(datas[1][:-1])
data = {
'input_ids': torch.tensor(index_of_words).to(self.device),
'token_type_ids': torch.tensor(token_type_ids).to(self.device),
'attention_mask': torch.tensor(attention_mask).to(self.device),
'labels': torch.tensor(label).to(self.device)
}
self.data.append(data)
file.close()
def __len__(self):
return len(self.data)
def __getitem__(self, index):
item = self.data[index]
return item
if __name__ == "__main__":
dataset = WellnessTextClassificationDataset()
print(dataset)위는 dataloader.py 의 코드입니다.
dataloader.py는 csv 와 같은 형태의 데이터를 pytorch 모델로 학습시키기 위해서 Dataset 클래스를 상속받아 구현해야 합니다.
앞선 KoGPT2 기반 Dataset과 마찬가지로, WellnessTextClassificationDataset은 Dataset을 상속받았으므로 init, len, getitem 메서드를 오버라이딩해야합니다.
len은 데이터셋의 크기를 리턴하고 getitem은 i번째 샘플을 찾는데 사용합니다.
import gc
import os
import numpy as np
import torch
from torch.utils.data import dataloader
from tqdm import tqdm
from transformers import AdamW
from model.classifier import KoBERTforSequenceClassfication
from model.dataloader import WellnessTextClassificationDataset
def train(device, epoch, model, optimizer, train_loader, save_step, save_ckpt_pa th, train_step=0):
losses = []
train_start_index = train_step + 1 if train_step != 0 else 0
total_train_step = len(train_loader)
model.train()
with tqdm(total=total_train_step, desc=f"Train({epoch})") as pbar:
pbar.update(train_step)
for i, data in enumerate(train_loader, train_start_index):
optimizer.zero_grad()
outputs = model(**data)
loss = outputs[0]
losses.append(loss.item())
loss.backward()
optimizer.step()
pbar.update(1)
pbar.set_postfix_str(f"Loss: {loss.item():.3f} ({np.mean(losses):.3f })")
if i >= total_train_step or i % save_step == 0:
torch.save({
'epoch': epoch, # 현재 학습 epoch
'model_state_dict': model.state_dict(), # 모델 저장
'optimizer_state_dict': optimizer.state_dict(), # 옵티마이 저 저장
'loss': loss.item(), # Loss 저장
'train_step': i, # 현재 진행한 학습
'total_train_step': len(train_loader) # 현재 epoch에 학습 할 총 train step
}, save_ckpt_path)
return np.mean(losses)
if __name__ == '__main__':
gc.collect()
torch.cuda.empty_cache()
root_path = "."
data_path = f"{root_path}/data/wellness_dialog_for_text_classification_all.t xt"
checkpoint_path = f"{root_path}/checkpoint"
save_ckpt_path = f"{checkpoint_path}/kobert-wellness-text-classification.pth "
n_epoch = 60 # Num of Epoch
batch_size = 4 # 배치 사이즈 #Colab이 돌아가지 않아 4로 했으며, 증가시켜도 무방
ctx = "cuda" if torch.cuda.is_available() else "cpu"
device = torch.device(ctx)
save_step = 100 # 학습 저장 주기
learning_rate = 5e-6 # Learning Rate
# WellnessTextClassificationDataset Data Loader
dataset = WellnessTextClassificationDataset(file_path=data_path, device=devi ce)
train_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, s huffle=True)
model = KoBERTforSequenceClassfication()
model.to(device)
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n fo r nd in no_decay)],
'weight_decay': 0.01},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=learning_rate)
pre_epoch, pre_loss, train_step = 0, 0, 0
if os.path.isfile(save_ckpt_path):
checkpoint = torch.load(save_ckpt_path, map_location=device)
pre_epoch = checkpoint['epoch']
train_step = checkpoint['train_step']
total_train_step = checkpoint['total_train_step']
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
print(f"load pretrain from: {save_ckpt_path}, epoch={pre_epoch}")
losses = []
offset = pre_epoch
for step in range(n_epoch):
epoch = step + offset
loss = train(device, epoch, model, optimizer, train_loader, save_step, s ave_ckpt_path, train_step)
losses.append(loss)
위 코드는 프로젝트 폴더 최상단에 위치하는 train.py 코드입니다.
학습시키는 코드를 작성합니다.
순전파를 거쳐 (이 때 KoBERTforSequenceClassfication의 forward가 실행됩니다) loss를 계산하고 backpropagation 시키면서 모델 파일을 저장합니다.
import torch
import torch.nn as nn
import random
from model.classifier import KoBERTforSequenceClassfication
from kobert_transformers import get_tokenizer
def load_wellness_answer():
root_path = "."
category_path = f"{root_path}/data/wellness_dialog_category.txt"
answer_path = f"{root_path}/data/wellness_dialog_answer.txt"
c_f = open(category_path, 'r')
a_f = open(answer_path, 'r')
category_lines = c_f.readlines()
answer_lines = a_f.readlines()
category = {}
answer = {}
for line_num, line_data in enumerate(category_lines):
data = line_data.split(' ')
category[data[1][:-1]] = data[0]
for line_num, line_data in enumerate(answer_lines):
data = line_data.split(' ')
keys = answer.keys()
if (data[0] in keys):
answer[data[0]] += [data[1][:-1]]
else:
answer[data[0]] = [data[1][:-1]]
return category, answer
def kobert_input(tokenizer, str, device=None, max_seq_len=512):
index_of_words = tokenizer.encode(str)
token_type_ids = [0] * len(index_of_words)
attention_mask = [1] * len(index_of_words)
# Padding Length
padding_length = max_seq_len - len(index_of_words)
# Zero Padding
index_of_words += [0] * padding_length
token_type_ids += [0] * padding_length
attention_mask += [0] * padding_length
data = {
'input_ids': torch.tensor([index_of_words]).to(device),
'token_type_ids': torch.tensor([token_type_ids]).to(device),
'attention_mask': torch.tensor([attention_mask]).to(device),
}
return data
if __name__ == "__main__":
root_path = "."
checkpoint_path = f"{root_path}/checkpoint"
save_ckpt_path = f"{checkpoint_path}/kobert-wellness-text-classification.pth"
# 답변과 카테고리 불러오기
category, answer = load_wellness_answer()
ctx = "cuda" if torch.cuda.is_available() else "cpu"
device = torch.device(ctx)
# 저장한 Checkpoint 불러오기
checkpoint = torch.load(save_ckpt_path, map_location=device)
model = KoBERTforSequenceClassfication()
model.load_state_dict(checkpoint['model_state_dict'])
model.to(ctx)
model.eval()
tokenizer = get_tokenizer()
while 1:
sent = input('\nQuestion: ') # '요즘 기분이 우울한 느낌이에요'
data = kobert_input(tokenizer, sent, device, 512)
if '종료' in sent:
break
output = model(**data)
logit = output[0]
softmax_logit = torch.softmax(logit, dim=-1)
softmax_logit = softmax_logit.squeeze()
max_index = torch.argmax(softmax_logit).item()
max_index_value = softmax_logit[torch.argmax(softmax_logit)].item()
answer_list = answer[category[str(max_index)]]
answer_len = len(answer_list) - 1
answer_index = random.randint(0, answer_len)
print(f'Answer: {answer_list[answer_index]}, index: {max_index}, softmax_value: {max_index_value}')
print('-' * 50)만들어진 모델 파일을 읽어 챗봇과 대화하기 위한 test.py 코드입니다.
kobert_input 함수로 입력을 토큰화해주어 모델에 input으로 넣어주면 모델이 어떤 상황인지 분류해냅니다.
load_wellness_answer 함수로 category.txt, answer.txt 파일을 읽어와 어떤 카테코리로 분류되었는지 설명과 챗봇의 응답을 확인할 수 있습니다.
출력 결과

출력된 값이 어떤 것을 의미하는지 설명하겠습니다.
응답 뒤에 출력된 정수 '22'는 분류된 클래스의 번호이고, '감정/눈물'은 22번 클래스에 대한 설명이고, 마지막 실수값은 softmax 값입니다. 22번 클래스일 확률이 97프로이고 가장 높은 확률이기 때문에 22번 클래스로 분류된 것입니다.
앞선 kogpt2 챗봇과 동일한 입력데이터를 넣어보았습니다.
1번부터 7번까지는 부정적인 입력이고 8번부터 10번까지는 긍정적인 입력에 대해 테스트한 결과입니다.
부정적인 상황에 대해서는 softmax값이 확연히 낮은 결과도 있지만 굉장히 잘 분리해내고 상황에 적절한 응답을 해주고 있습니다. 하지만 긍정적인 입력에는 전혀 입력된 문장과 호응이 되고 있지 않습니다.
이는 당연한 결과 입니다. 학습시킨 데이터셋은 상담 데이터이기 때문에 긍정적인 상황에 대한 데이터는 거의 없는 수준입니다. 그래서 KoBERT 기반 챗봇은 위로형 챗봇으로 이름을 정했고, 앞선 KoGPT2 기반 챗봇과 함께 서비스하고 있습니다. 사용자가 어플에서 원하는 챗봇을 설정할 수 있게 구현했습니다. 이에 대해서는 이 글의 후반부인 [4] 활용 현황에서 더 자세히 보여드리겠습니다.
[3] api 서버
코드 전문에 대한 링크입니다.
flask 웹 프레임워크
IDE 설치, 가상 환경 생성
저는 IDE로 PyCharm 을 선택했습니다. JetBrains 사의 제품이 익숙해서 선택했습니다.
해당 IDE에서 new project를 만들 때 옵션을 클릭해 쉽게 가상 환경을 만들 수 있습니다.

라이브러리 설치
라이브러리를 설치해주어야 합니다.
감정 분류 모델, kobert 기반 챗봇, kogpt2 기반 챗봇 모델이 모두 같은 환경에서 실행되어야하기 때문에 충돌이 일어날 확률이 훨씬 높습니다.
먼저 학습할 때 사용했던 requirements.txt 파일을 이용해 설치를 하는데, 충돌이 일어난다면 에러를 잘 읽고 최대한 버전 오류가 안나게 하면 좋습니다.
pip install --no-deps numpy==원하는버전하지만 저는 그렇게 해결할 수가 없어서, 결국 의존성을 무시하고 강제로 라이브러리를 설치해보면서 경험적으로 가능한 환경을 찾았습니다. --no-deps 가 의존성을 무시하고 강제로 라이브러리를 설치하라는 옵션입니다.
pip freeze > requirements.txt환경을 모두 구축한 다음에는 현재 설치된 상황을 명령어 그대로 requirements.txt 파일에 저장해 얼려둡니다. 파일 이름은 자유롭게 지정할 수 있습니다.
pip install --no-deps -r requirements.txt이후에 새로운 환경에서 라이브러리를 재설치해야할 때에는 위의 명령어로 설치할 수 있습니다.
코드 작성

특정 모델에 필요한 파일은 directory 별로 구분해두었습니다.
kobert 기반 챗봇을 구현하는데 필요한 파일은 model.chatbot.kobert 폴더에,
kogpt2 기반 챗봇을 구현하는데 필요한 파일은 model.chatbot.kogpt2 폴더에,
이 글에서는 다루지 않았지만 감정 분류하는데 필요한 파일은 model.emotion 폴더에 넣었습니다.
학습을 시키는 것이 아니라서
큼직하게 생각하면 분류 모델은 모델을 불러온 다음 분류기만 있으면 되고,
kogpt2는 모델을 불러오는 부분만 있으면 되기 때문에 간단히 정리해 구성했습니다.
이 외에 checkpoint에는 앞서 train할 때 저장했던 모델 파일을 저장해두었습니다.
data에는 .txt, .csv 와 같은 문서 파일을 저장해두었습니다.
preprocess 에는 데이터 전처리할 때 사용하는 코드를 저장해두었습니다.
util 에는 감정 관련 class를 만들어 로직에서 중복되는 부분을 집어 class의 method로 작성해두었습니다.
아래의 코드 내용은 프로젝트 root에 있는 app.py의 내용입니다.
import os
from model.chatbot.kogpt2 import chatbot as ch_kogpt2
from model.chatbot.kobert import chatbot as ch_kobert
from model.emotion import service as emotion
from util.emotion import Emotion
from util.depression import Depression
from flask import Flask, request, jsonify
from kss import split_sentences
앞서 directory 구조를 대충 살펴보았기 때문에 어떤 것을 의미하는 것인지 눈에 띄는 것이 많을 것입니다.
맨 마지막 줄은 NLP에서 널리 사용되고 있는 kss라는 한국어 문장 분류 라이브러리를 사용하기 위해 불러왔습니다.
app = Flask(__name__)
Emotion = Emotion()
Depression = Depression()
@app.route('/')
def hello():
return "deep learning server is running 💗"
통신이 될 수 있는 상황인지 알기 위해 root 경로 호출했을 때 간단한 string을 반환하도록 api를 작성했습니다.
@app.route('/emotion')
def classifyEmotion():
sentence = request.args.get("s")
if sentence is None or len(sentence) == 0:
return jsonify({
"emotion_no": 2,
"emotion": "중립"
})
result = emotion.predict(sentence)
print("[*] 감정 분석 결과: " + Emotion.to_string(result))
return jsonify({
"emotion_no": int(result),
"emotion": Emotion.to_string(result)
})호출 방법: /emotion?s=분석해주기를 원하는 문장
한 두 문장을 입력으로 받고 어떤 감정에 해당하는지 분류해 응답합니다.
request query의 값이 비어있으면 BadRequest 400으로 응답했는데, 기본값으로 중립을 두는 것이 더 나을 것 같아 기본값을 지정했습니다.
@app.route('/diary')
def classifyEmotionDiary():
sentence = request.args.get("s")
if sentence is None or len(sentence) == 0:
return jsonify({
"joy": 0,
"hope": 0,
"neutrality": 0,
"anger": 0,
"sadness": 0,
"anxiety": 0,
"tiredness": 0,
"regret": 0,
"depression": 0
})
predict, dep_predict = predictDiary(sentence)
return jsonify({
"joy": predict[Emotion.JOY],
"hope": predict[Emotion.HOPE],
"neutrality": predict[Emotion.NEUTRALITY],
"anger": predict[Emotion.ANGER],
"sadness": predict[Emotion.SADNESS],
"anxiety": predict[Emotion.ANXIETY],
"tiredness": predict[Emotion.TIREDNESS],
"regret": predict[Emotion.REGRET],
"depression": dep_predict
})
def predictDiary(s):
total_cnt = 0.0
dep_cnt = 0
predict = [0.0 for _ in range(8)]
for sent in split_sentences(s):
total_cnt += 1
predict[emotion.predict(sent)] += 1
if emotion.predict_depression(sent) == Depression.DEPRESS:
dep_cnt += 1
for i in range(8):
predict[i] = float("{:.2f}".format(predict[i] / total_cnt))
dep_cnt = float("{:.2f}".format(dep_cnt/total_cnt))
return predict, dep_cnt호출 방법: /diary?s=분석해주기를 원하는 일기
일기 한 개의 모든 내용을 입력으로 받고 각 감정의 비율을 계산하고 우울한 문장의 비율도 계산하여 함께 응답합니다.
@app.route('/chatbot/g')
def reactChatbotV1():
sentence = request.args.get("s")
if sentence is None or len(sentence) == 0:
return jsonify({
"answer": "듣고 있어요. 더 말씀해주세요~ (끄덕끄덕)"
})
answer = ch_kogpt2.predict(sentence)
return jsonify({
"answer": answer
})
@app.route('/chatbot/b')
def reactChatbotV2():
sentence = request.args.get("s")
if sentence is None or len(sentence) == 0:
return jsonify({
"answer": "듣고 있어요. 더 말씀해주세요~ (끄덕끄덕)"
})
answer, category, desc, softmax = ch_kobert.chat(sentence)
return jsonify({
"answer": answer
})호출 방법: /chatbot/g?s=입력, /chatbot/b?s=입력
다른 버전의 chatbot은 다른 url을 사용해 호출해야 하도록 구현하였습니다.
입력이 비었더라도 기본적으로 "듣고 있어요. 더 말씀해주세요~ (끄덕끄덕)"으로 응답합니다.
if __name__ == '__main__':
app.run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))ip와 port를 지정하여 flask 어플을 실행시키는 코드를 작성합니다.
docker image 빌드, 업로드
Dockerfile
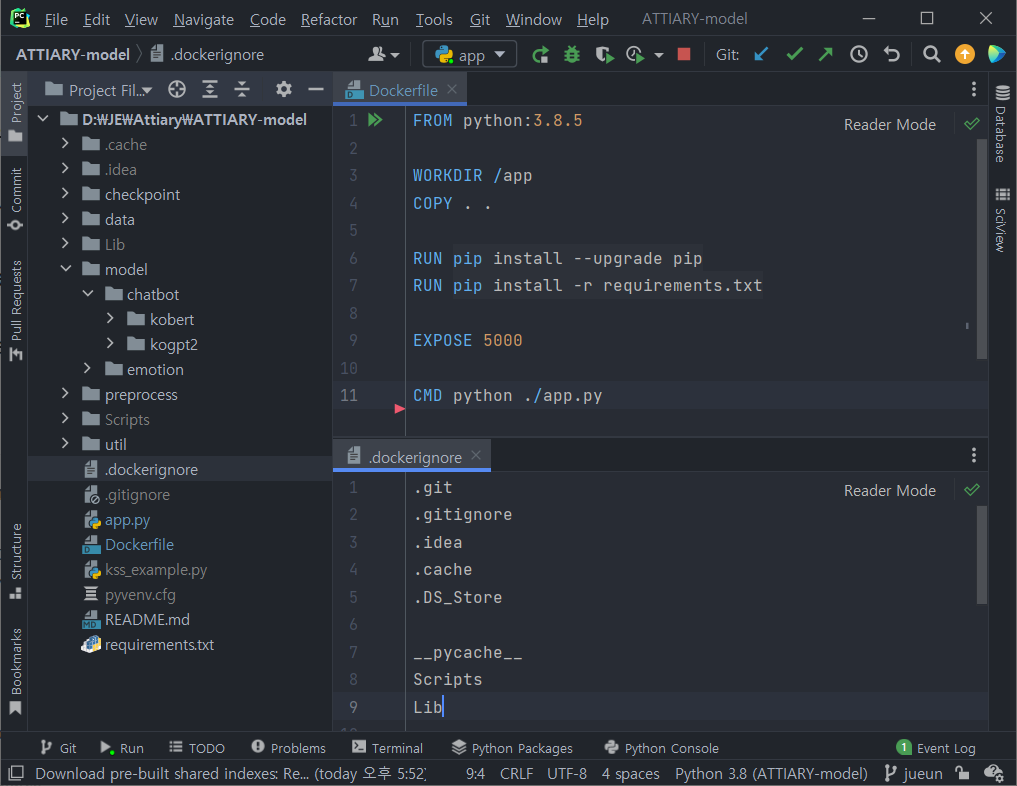
프로젝트 최상단 경로에 Dockerfile을 작성합니다.
FROM python:3.8.5
WORKDIR /app
COPY . .
RUN pip install --upgrade pip
RUN pip install -r requirements.txt
EXPOSE 5000
CMD python ./app.pypython을 설치하고 /app 밑을 working directory로 지정합니다. .dockerignore에 작성된 파일이나 폴더를 무시하고 나머지의 파일들을 복사합니다. pip을 최신 버전으로 업그레이드한 뒤 requirements.txt에 작성된 라이브러리를 설치합니다. 5000번 포트를 외부로 개방할 것이라고 설정한 뒤 실행 명령어를 작성해줍니다.
.dockerignore
꼭 필요한 파일로만 image를 build하도록 하여, docker image를 최적화하는 방법 중 하나입니다.
.git
.gitignore
.idea
.cache
.DS_Store
__pycache__
Scripts
Lib
*.md
*.cfg
preprocess
kss_example.py
*/__pycache__/*원하는 파일, 폴더명, 특정 확장자로 끝나는 파일 등등 자유롭게 작성할 수 있습니다.

프로젝트 최상단 경로에 위치해야하며, Dockerfile이 실행될 때 자동으로 해당 파일을 인식하여 적힌 파일이나 폴더는 무시합니다.
image build
docker build --tag attiary_model:2.0 .--tag 옵션에 이미지 이름과 태그를 지정할 수 있습니다.
주의할 부분은 맨 마지막에 . 을 빼먹지 않고 작성해야 합니다.
저는 이 과정에서 7~8분 정도 걸립니다.
image push
docker image tag attiary_model:2.0 hoit1302/attiary_model:latest
docker push hoit1302/attiary_model:latest이미지 태그의 이름을 dockerhub에 있는 username/reponame:원하는태그 로 변경합니다. 그리고 push하면 됩니다.이 과정에서 로그인을 요구할 수도 있습니다.
네트워크 상황에 따라 업로드에 소요되는 시간은 다양합니다. 좋을 때는 20분 정도에서 업로드가 완료될 때도 있고 안좋을 때는 4시간이 소요된 적도 있습니다.

push한 repository에서 잘 push 되었는지 확인할 수 있습니다.
클라우드 서버로 배포
문제점

백엔드 개발 후에 서버 AWS를 사용하여 서버를 몇 번 운영해보았던 경험에 비추어 손쉽게 프리 티어의 ec2 서버에 docker container를 올렸더니 어플리케이션을 구동시키다가 Killed라는 강렬한 문구를 남기고 죽어버렸습니다. 심지어 서버 컴퓨터에서 전혀 응답을 받을 수 없어서 재부팅 시켜야 했습니다.
memory가 절대적으로 부족했던 것입니다.
프리티어에서는 디스크 공간을 memory로 쓸 수 있도록 swap 시켜봤자 최대 2GB였기 때문에 딥러닝 서버를 구동시키기에는 역부족이었습니다.
이렇게 현실적인 벽에 부딪혔을 때, 학교 측에서 4월 말에 tencent cloud를 지원해주었습니다.
텐센트 클라우드

GPU based의 instance를 띄우고 작업했습니다.
deploy.sh
간단히 docker 명령어를 모아둔 deploy shell script를 작성하였습니다.
echo "[*] 실행되고 있는 컨테이너 중지"
sudo docker stop atti_model
echo "[*] 중지된 컨테이너 삭제"
sudo docker rm atti_model
echo "[*] 새로운 이미지 pull 받기"
sudo docker pull hoit1302/attiary_model:latest
echo "[*] 새로운 이미지 확인하기"
sudo docker images
echo "[*] 새로운 이미지 백그라운드로 실행하기"
sudo docker run --name atti_model -d -p 5000:5000 hoit1302/attiary_model:latest
echo "[*] 실행되고 있지 않는 이미지 삭제하기"
sudo docker image prune -a -f
echo "[*] 삭제된 이미지 확인하기"
sudo docker imagesatti_model 부분에는 원하는 container 이름을 적고
hoit1302/attiary_model은 이미지를 올린 docker의 계정과 repo를 지정하면 됩니다.
run 명령할 때 -d 옵션이 background로 실행할 수 있는 옵션입니다.
해당 옵션을 빼고 실행시키면 제 컴퓨터와 서버 컴퓨터의 연결 세션이 끊겼을 때 컨테이너가 중단됩니다.
로그 보기
도커 컨테이너의 로그를 보는 명령어입니다.
docker logs atti_model아래 10줄의 로그 보는 방법입니다. --tail 옵션에 원하는 숫자를 넣을 수 있습니다.
docker logs --tail 10 atti_modeldocker image hoit1302/attiary_model:2.1을 gpu 서버에서 실행시킨 로그입니다.

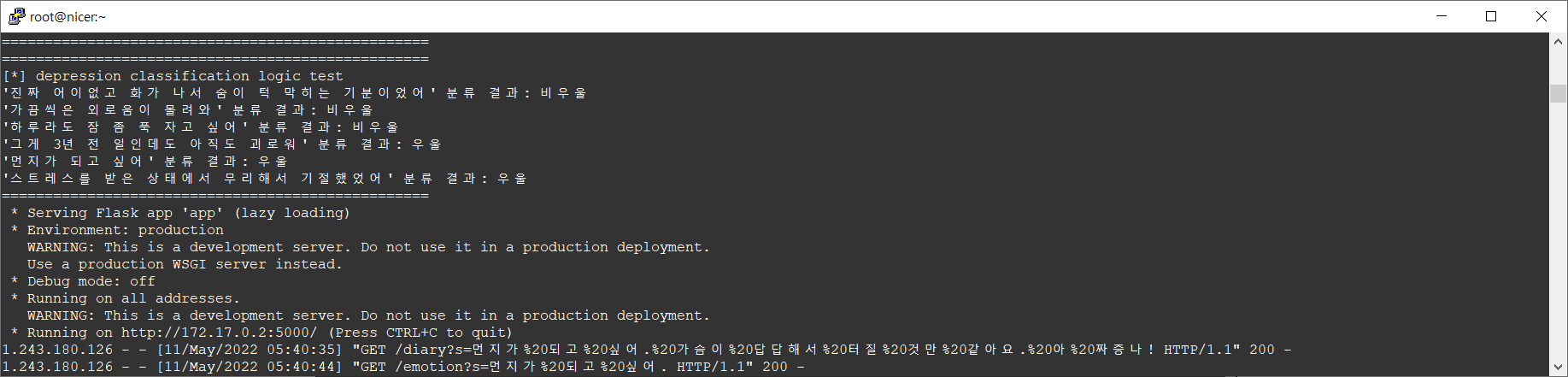

5일 전에 올린 컨테이너가 잘 실행되고 있음을 확인할 수 있습니다.
[4] 활용 현황

저는 졸업프로젝트로 심리 케어 목적의 일기 어플, "아띠어리"을 개발했습니다.
1. 챗봇
챗봇은 일기를 작성하고 있을 때 엔터키를 누르면 줄바꿈이 되고 입력된 내용에 대한 반응을 서버에 요청하게 됩니다.
그러면 노란 병아리의 아띠라는 친구가 사용자가 작성한 내용에 대해 공감하거나 위로해주는 반응을 보입니다.
오늘은 너무 슬픈 날이었어.
친구가 당일에 약속을 취소했거든.
사실 요즘들어 연락이 잘 안된다는 느낌이 있었거든.
속상해... 내 잘못같고...
오늘은 일찍 잘거야.
같은 일기 내용에 대한 챗봇의 응답을 비교해보겠습니다.
먼저 kobert 챗봇입니다.

정말 위로를 잘해주고 있는 모습을 볼 수 있습니다. 그래서 kobert 챗봇의 이름은 위로형 아띠로 지었습니다. 따뜻한 성격을 가지고 있어 부정적인 감정이 느껴질 때 사용하면 좋다고 사용자에게 어플 내에서 안내하고 있습니다.
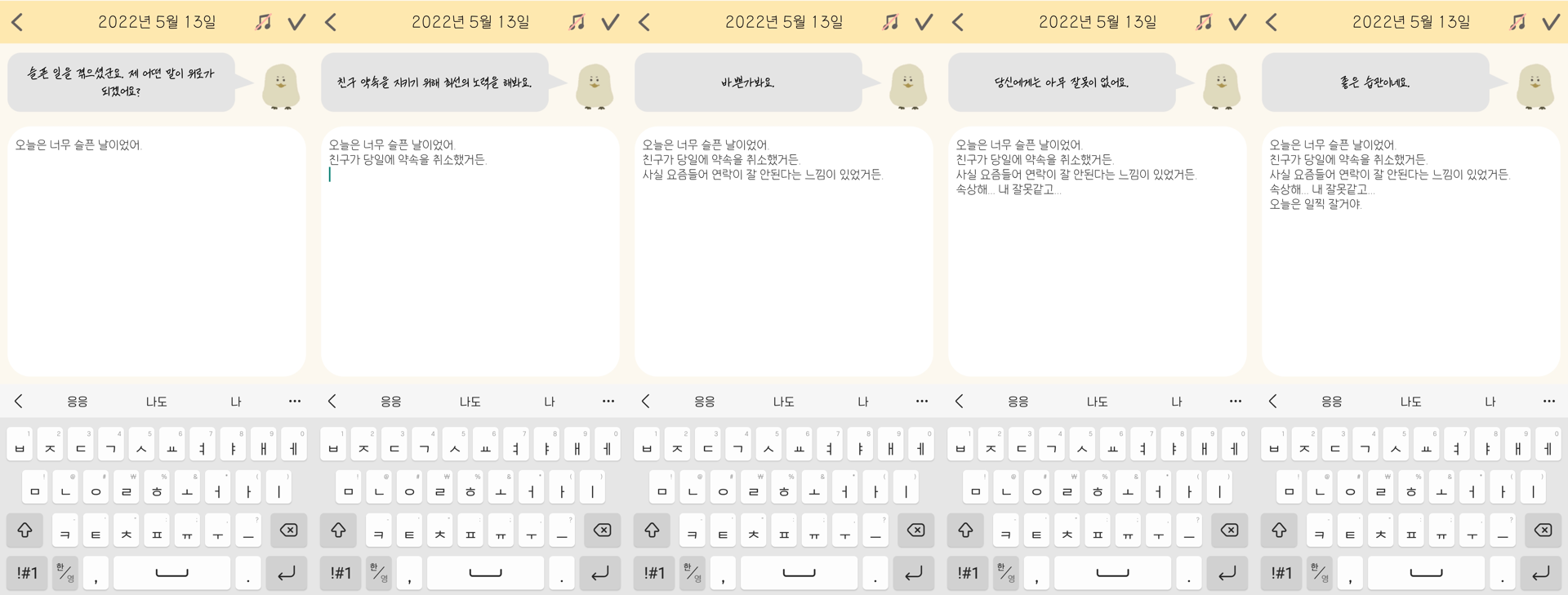
kogpt2 챗봇은 어떤 반응을 하는지 살펴보겠습니다.
전반적으로 답변이 짧다는 것을 느낄 수 있습니다. 그리고 조금 더 일상적인 대화를 하고 있는 것처럼 느껴집니다.
그래서 kogpt2 챗봇의 이름은 공감형 아띠로 지었습니다.
내용에 따라 다양한 반응을 보이기 때문에 발랄한 성격을 가지고 있다고 사용자에게 안내하고 있습니다.
두 챗봇 모두 응답 속도는 빠른 편이고 사용자는 사용하고 싶은 챗봇을 설정할 수 있게 어플을 구현하였습니다.
2. 중립/슬픔/분노/불안/피곤/후회 분류

아띠어리는 일기를 작성하고 있을 때 엔터키를 누르면 줄바꿈이 되고 챗봇이 반응을 해주기도 하는데, 이 때 감지된 감정과 알맞는 배경음악으로 변경해 들려주는 기능도 있습니다.
이 기능 (실시간으로 감정을 감지해 배경 음악을 변경해주는 기능)도 사용자가 사용을 원하지 않으면 끄도록 설정할 수 있습니다.

많이 감지된 감정 순으로 보여주고 첫번째 감정이 대표 감정 이미지와 연결됩니다.
각 감정 별로 3단계씩 다른 이미지가 존재합니다. 첫번째 두번째의 대표 감정은 기쁨이지만 정도에 따라 다른 이미지를 보여주고 있습니다.
아띠가 하고 싶은 말이 있대요! 부분도 감지된 대표 감정에 따라 내용이 달라집니다.
이런 기능에 감정 분류가 사용됩니다.
처음에는 한번에 기쁨/희망/중립/슬픔/분노/불안/피곤/후회 8가지 감정을 분류해낼 수 있는 모델을 제작했습니다. 한 달 동안 거의 매일 밤마다 온라인 회의로 모여 직접 만 개의 문장을 감정으로 분류하는 작업을 했습니다. 하지만 해당 모델은 정확도가 80%에 그쳤습니다. 틀릴 확률이 20% 정도나 되는 모델을 사용할 수는 없었습니다.
그래서 방법을 바꾸어 이 글에서 기술한 KoBERT 상황 판단 분류 모델을 활용했습니다. 359개의 각 클래스를 특정 감정과 1:1로 대응시켰습니다.
학습시킨 데이터는 상담 데이터이기 때문에 부정적인 데이터가 주를 이루고 있습니다. 그래서 먼저 긍정과 중립 부정으로 3중 분류 모델을 거친 후 부정으로 분류된 입력 데이터는 다시 KoBERT 상황 판단 분류 모델을 거쳐 6가지 감정(중립/슬픔/분노/불안/피곤/후회) 중 한 가지로 분류됩니다.
3. 우울 분류
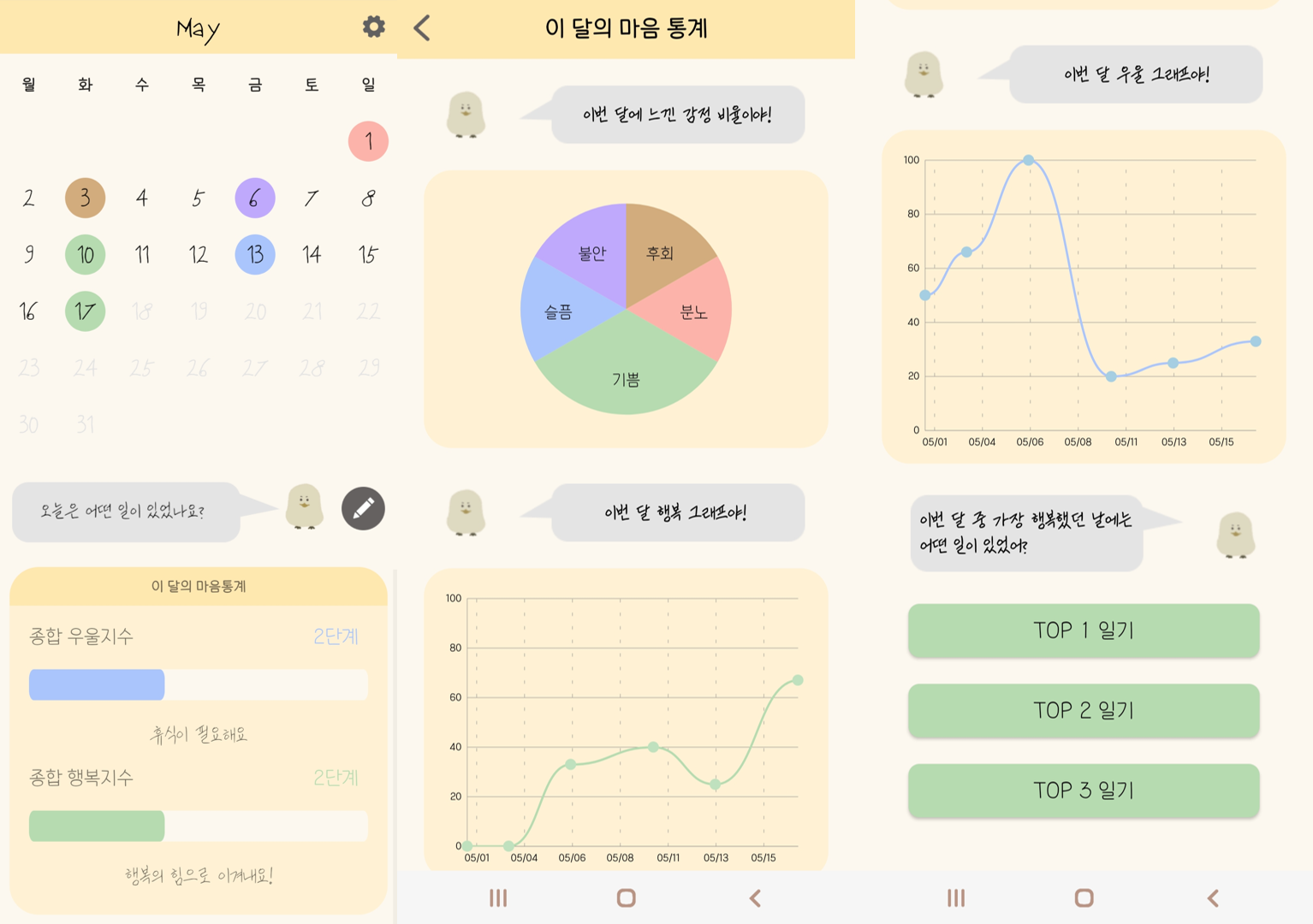
일기를 다 쓰고 나면 캘린더 화면에서 각 달의 종합 우울지수와 행복지수를 계산해 보여줍니다.
종합 우울지수와 행복지수를 나타내는 부분을 클릭하면 해당하는 달의 일기를 다른 형식으로 보여줍니다.
대표 감정들은 파이차트로 보여주고, 행복 지수와 우울 지수의 추이를 그래프로 보여줍니다.
종합 행복지수는 행복/희망이 나타난 비율로 간단하게 산술 평균을 냅니다.종합 우울지수는 슬픔/분노/불안/피곤/후회 감정과 더불어 우울을 추가로 감지하여 가중치를 둡니다.
따라서 우울과 비우울을 분류하는 모델이 필요했습니다.

저희 팀은 앞서 설명한 KoBERT 기반 359가지의 분류 모델을 또 활용하여 우울/비우울 분류기를 손쉽게 구현했습니다.
팀원들과 회의하여 위의 상황들로 분류되었을 때 우울로 판단되도록 구현했습니다.
우울 지수가 특정 값 이상으로 지속되는 경우에는 상담을 권유하거나 전문의와 연결지어주는 방식으로 서비스를 조금 더 확장시킬 수 있을 것 같습니다.
[5] 느낀 점
기술과는 관련이 없고, 개인적으로 느낀 점을 작성했습니다.
1. HW에도 관심을 가지자
학습을 시킬 때에도, classifier만 있는 웹 서버를 실행시킬 때에도 하드웨어의 한계에 참 많이 부딪혔던 것 같습니다. 코드를 보고 또봐도 이제 더 이상 오류가 없어보이는데 돌아가지 않는 이유는 근본적으로 하드웨어 자원이 부족해서 였던 경우가 많았습니다. software 개발자이지만 hardware에도 관심을 가지고 주목해야한다고 했던 교수님의 말씀이 많이 떠올랐습니다.
2. 필요없는 공부는 없구나
GPU가 여러 대인 환경에서 병렬적으로 코드를 수행하는 부분도 신기했습니다. 클라우드 수업 시간에 배웠는데 이렇게 빨리 병렬 컴퓨팅 지식을 활용해 실전에서 오류를 풀어낼거라고는 생각도 못했습니다.
3. 새로운 기술도 오픈 마인드로
딥러닝/인공지능에 대한 기반 지식이 전혀 없을 때 프로젝트를 시작했고 주언어도 python이 아니라서 정말 간단한 코드를 작성하거나 라이브러리 의존성 문제에도 정말 많이 힘들어 했던 기억이 납니다. 말로만 들어보았던 conda, jupyter 모두 간단하게 나마 다뤄보게 되었고 새롭게 접한 기술이 정말 많은 것 같습니다.
이 글에서는 다루지 않았지만 안드로이드 개발에도 꽤 참여했습니다. 안드로이드 역시 처음으로 개발해보게 되었고, 언어도 너무나 생소한 코틀린으로 시작하게 되었는데 도서관에서 빌린 책 몇 권을 발췌해 보고 구글링하면서 또 개발이 되었네요.
새로운 분야에 대한 두려움은 항상 있는데 프로젝트가 끝날 무렵이면 많이 성장한 것 같아서 너무 뿌듯합니다. 이런 성취감이 좋아서 개발자를 꿈꾸게 되는 것 같습니다.
4. 좋은 팀원...!
프로젝트가 순탄하게 이어져왔고 개발도 완성이 한 것에는 팀원들을 잘 만난 영향이 큰 것 같습니다. 각자 맡은 부분에 대해서 고통을 토로하긴 했지만 결국 각자가 맡은 부분은 묵묵히 해냈습니다. 개발하다보면 기능을 없애거나 축소하게 되는 게 다반사인데 수정한 부분이 없는 것 같습니다. 참 모두가 멋져요!!(팀명 NICER🥰) 이런 조직에 들어가기 위해서 많은 노력을 들일 필요가 있다는 동기부여도 많이 얻은 것 같습니다.
'NLP' 카테고리의 다른 글
| [Python, KoBERT] 다중 감정 분류 모델 구현하기 (huggingface로 이전 방법 O) (19) | 2021.11.23 |
|---|