1. BERT, KoBERT란?
구글에서 2018년에 공개한 BERT는 등장과 동시에 수많은 NLP 태스크에서 최고 성능을 보여주면서 NLP의 한 획을 그은 모델로 평가받고 있다. 양방향성을 지향하고 있기 때문이다.(B: bidirection) BERT 모델은 문맥 특성을 활용하고 있고, 대용량 말뭉치로 사전 학습이 이미 진행되어 언어에 대한 이해도도 높다. 하지만 BERT는 한국어에 대해서 영어보다 정확도가 떨어진다고 한다.
오늘 기술해볼 KoBERT 모델은 SKTBrain에서 공개했는데, 한국어 위키 5백만 문장과 한국어 뉴스 2천만 문장을 학습한 모델이다. 자신의 사용 목적에 따라 파인튜닝이 가능하기 때문에 output layer만을 추가로 달아주면 원하는 결과를 출력해낼 수 있다. 많은 BERT 모델 중에서도 KoBERT를 사용한 이유는 "한국어"에 대해 많은 사전 학습이 이루어져 있고, 감정을 분석할 때, 긍정과 부정만으로 분류하는 것이 아닌 다중 분류가 가능한 것이 강점이기 때문이다.
이 포스팅에서 하는 작업은 바로 파인 튜닝(Fine-tuning)에 해당한다. 다른 작업에 대해서 파라미터 재조정을 위한 추가 훈련 과정을 거치는 것을 말한다. 예시를 들어보면, 우리가 하고 싶은 작업이 우울증 경향 문헌 분류라고 하였을 때, 이미 위키피디아 등으로 사전 학습된 BERT 위에 분류를 위한 신경망을 한 층 추가하는 것이다. 이미 BERT가 언어 모델 사전 학습 과정에서 얻은 지식을 활용할 수 있으므로 우울증 경향 문헌 분류에서 보다 더 좋은 성능을 얻을 수 있다.
2. 어려웠던 점
KoBERT 모델을 제공하던 기존 서버가 완전히 닫히고 hugingface hub로 이전되었다.
하지만 여전히 github에는 두가지의 method를 제공하고 있고
바뀐 서버로의 예제 코드를 제공해주고 있지 않아
코드를 이해하고 작성하는데 오랜 시간이 걸렸다.


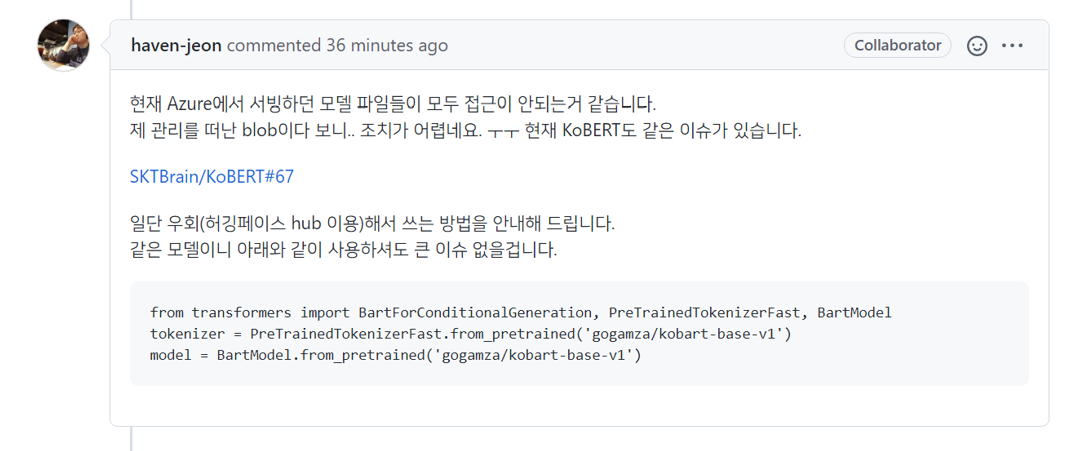
해당 문제를 발견해 발행된 issue에 무려 36분 전에 개발자분께서 comment를 남겨주셨었다. 내내 it 기술을 다루어도 꽤나 오랫동안 검증받고 서비스가 많이 되고 있는 안정적인 언어, 프레임워크, 모델들만 사용하다가 갑자기 신기술의 정점에 서있는 것 같아 조금 신기했다.
3. 데이터셋 설명, 코딩 환경
네이버 리뷰 2중 분류 예제 코드를 기반으로 작성하였고 데이터는 AiHub의 감정 분류를 위한 대화 음성 데이터셋을 이용했다. 해당 데이터셋에서는 감정은 7가지 감정(happiness-행복, angry-분노, disgust-혐오, fear-공포, neutral-중립, sadness-슬픔, surprise-놀람) 7가지로 분류해주고 있다. colab 환경에서 코딩하고 테스트해보았다.
4. 실습 설명, 코드
1. Colab 환경을 설정하기
!pip install gluonnlp pandas tqdm
!pip install mxnet
!pip install sentencepiece==0.1.91
!pip install transformers==4.8.2
!pip install torch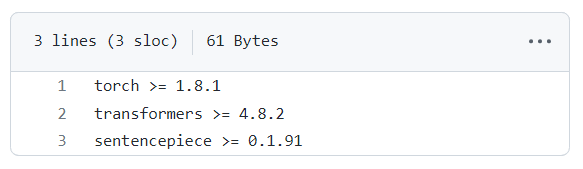
현재 요구하는 사양은 그림과 같다.
KoBERT 가 요구하는 최신 버전 정보는 이 공식 오픈소스 링크#에서 확인할 수 있다.
2. github에서 KoBERT 파일을 로드 및 KoBERT모델 불러오기
!pip install 'git+https://github.com/SKTBrain/KoBERT.git#egg=kobert_tokenizer&subdirectory=kobert_hf'https://github.com/SKTBrain/KoBERT/tree/master/kobert_hf 의 kobert_tokenizer 폴더를 다운받는 코드이다.
!pip install git+https://git@github.com/SKTBrain/KoBERT.git@masterhttps://github.com/SKTBrain/KoBERT 의 파일들을 다운받는 코드이다.
from kobert.pytorch_kobert import get_kobert_model
from kobert_tokenizer import KoBERTTokenizer
tokenizer = KoBERTTokenizer.from_pretrained('skt/kobert-base-v1')
bertmodel, vocab = get_kobert_model('skt/kobert-base-v1',tokenizer.vocab_file)BERT는 이미 누군가가 학습해둔 모델을 사용한다(pre-trained model)는 것을 뜻한다. 따라서 사용하는 model과 tokenizer는 항상 mapping 관계여야 한다. 예를 들어서 U 팀이 개발한 BERT를 사용하는데, V팀이 개발한 BERT의 tokenizer를 사용하면 model은 텍스트를 이해할 수 없다. U팀의 BERT의 토크나이저는 '우리'라는 단어를 23번으로 int encoding하는 반면에, V라는 BERT의 tokenizer는 '우리'라는 단어를 103번으로 int encoding해 단어와 mapping 되는 정보 자체가 달라지기 때문이다. 이 부분은 뒤에서 간단히 진행해본 실습에서 더 자세히 다뤄볼 것이다.
한 줄 한 줄 자세히 설명해보면,
1: https://github.com/SKTBrain/KoBERT 의 kobert 폴더의 pytorch_kobert.py 파일에서 get_kobert_model 메서드를 불러오는 코드이다.

2: https://github.com/SKTBrain/KoBERT/tree/master/kobert_hf 의 kobert_tokenizer 폴더의 kobert_tokenizer.py 파일에서 KoBERTTokenizer 클래스를 불러오는 코드이다.

3, 4: 불러온 메서드를 호출하고 클래스를 가져와 각각 tokenizer와, model, vocabulary를 불러왔다.
이렇게 해당 실습에 필요한 KoBERT모델을 불러오는 코드 설명은 끝났다.
아래의 방법은 또 다른 방법으로 KoBERT 모델을 불러오는 코드이다.
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("skt/kobert-base-v1")
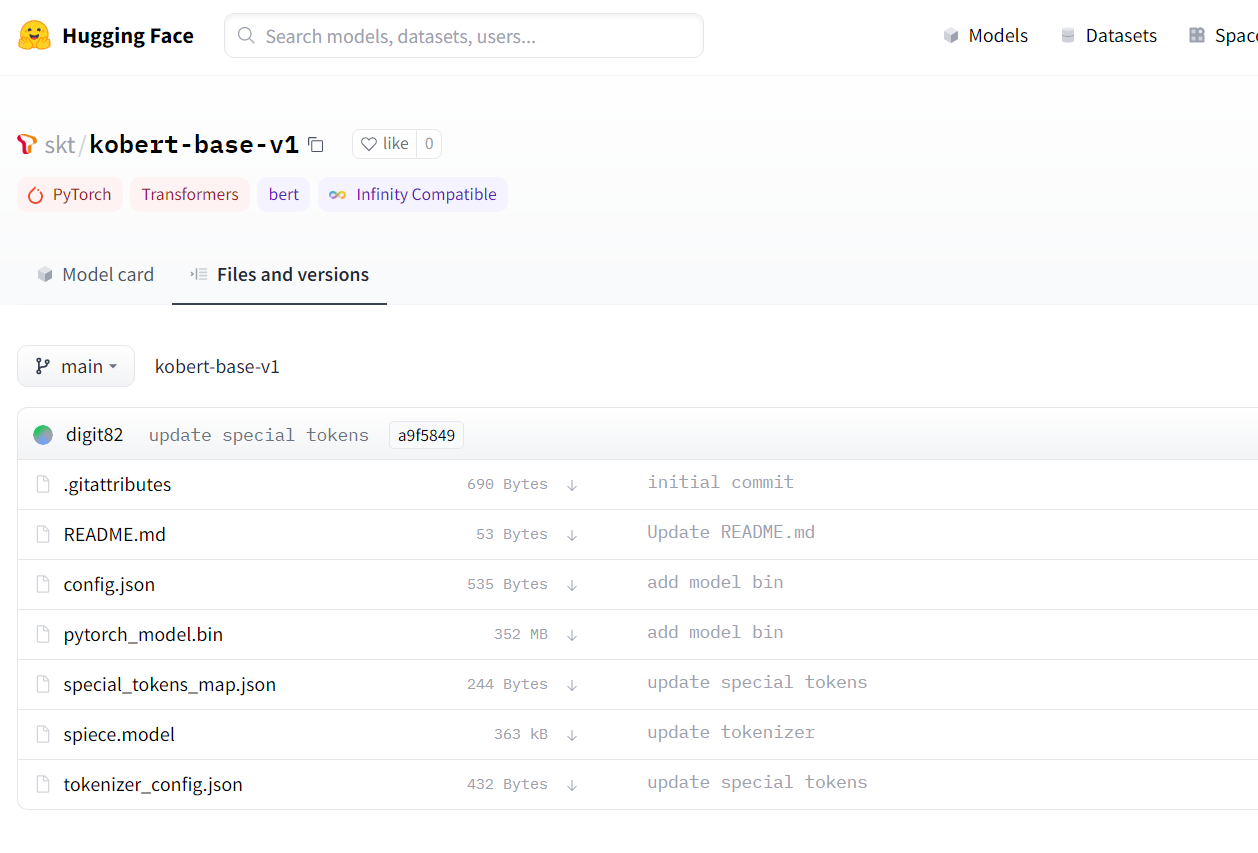
model = AutoModel.from_pretrained("skt/kobert-base-v1")github을 통한 다운로드 없이 사용할 수 있다. 하지만 해당 코드로는 vocab에 접근하기 어렵다. 각자의 상황에 맞게 쓰면 될 것 같다.
huggingface 사이트에 skt/kobert-base-v1으로 올라와있는 것을 확인할 수 있다.
3. 필요한 라이브러리 불러오기
import torch
from torch import nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import gluonnlp as nlp
import numpy as np
from tqdm import tqdm, tqdm_notebook
import pandas as pd
#transformers
from transformers import AdamW
from transformers.optimization import get_cosine_schedule_with_warmup
from transformers import BertModel
#GPU 사용 시
device = torch.device("cuda:0")사전 학습된 BERT를 사용할 때는 transformers라는 패키지를 자주 사용한다.
또한, 학습시간을 줄이기 위해, GPU를 사용했다.
4. 데이터셋 불러오기

왼쪽 상단에 폴더 버튼을 누르고 업로드 버튼을 눌러서 로컬에 있는 파일을 업로드할 수 있다. 오늘 실습에 필요한 '감정분류데이터셋.csv' 파일을 업로드하면 위 그림과 같이 파일이 생긴다.
data = pd.read_csv('감정분류데이터셋.csv', encoding='cp949')파일 이름을 지정해 pandas library로 열어주었다.

해당 데이터셋은 위와 같이 column 명이 지정되어 있다.
data.loc[(data['상황'] == "fear"), '상황'] = 0 #공포 => 0
data.loc[(data['상황'] == "surprise"), '상황'] = 1 #놀람 => 1
data.loc[(data['상황'] == "angry"), '상황'] = 2 #분노 => 2
data.loc[(data['상황'] == "sadness"), '상황'] = 3 #슬픔 => 3
data.loc[(data['상황'] == "neutral"), '상황'] = 4 #중립 => 4
data.loc[(data['상황'] == "happiness"), '상황'] = 5 #행복 => 5
data.loc[(data['상황'] == "disgust"), '상황'] = 6 #혐오 => 6
data_list = []
for ques, label in zip(data['발화문'], data['상황']) :
data = []
data.append(ques)
data.append(str(label))
data_list.append(data)7개의 감정 class를 0~6 숫자에 대응시켜 data_list에 담아준다.
5. 입력 데이터셋을 토큰화하기
class BERTDataset(Dataset):
def __init__(self, dataset, sent_idx, label_idx, bert_tokenizer,vocab, max_len,
pad, pair):
transform = nlp.data.BERTSentenceTransform(
bert_tokenizer, max_seq_length=max_len,vocab=vocab, pad=pad, pair=pair)
self.sentences = [transform([i[sent_idx]]) for i in dataset]
self.labels = [np.int32(i[label_idx]) for i in dataset]
def __getitem__(self, i):
return (self.sentences[i] + (self.labels[i], ))
def __len__(self):
return (len(self.labels))각 데이터가 BERT 모델의 입력으로 들어갈 수 있도록 tokenization, int encoding, padding 등을 해주는 코드이다.
<tokenization 부가 설명>
"tokenization" 이 내용에 대해서 조금 저 자세히 적어보려고 한다.
참고로 이 부분은 다중 분류를 위한 코드와 연결되지 않는다. 그저 이해를 돕기 위해 부가 설명된 부분이다 !!
참고로, 현재 사용한 모델은 KoBERT 이지만, KcBERT에서 vocab file을 보기 쉽게 text 파일로 보여주고 있어, 먼저 KcBERT로 토큰화, 정수 인코딩, padding을 보고 KoBERT에서도 다시 한번 실험해보고자 한다.
KcBERT 모델에서의 토큰화와 정수 인코딩

KcBERT 모델을 만들기 위한 기존 훈련 데이터로부터 만들어진 vocabulary는 위와 같은 형태를 띈다.
사진을 누르면 KcBERT 공식 repo로 연결된다.
이 vocab가 어떻게 대응되는지 살펴보기 위해 아주 간단한 코드를 직접 작성해보았다.
!pip install --no-cache-dir transformers sentencepiece
from transformers import AutoTokenizer, AutoModelForMaskedLM
# kcbert의 tokenizer와 모델을 불러옴.
kcbert_tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-base")
kcbert = AutoModelForMaskedLM.from_pretrained("beomi/kcbert-base")
result = kcbert_tokenizer.tokenize("너는 내년 대선 때 투표할 수 있어?")
print(result)
print(kcbert_tokenizer.vocab['대선'])
print([kcbert_tokenizer.encode(token) for token in result])
새로운 colab 파일을 열어 단 4줄의 코드로 model과 tokenizer를 불러올 수 있다.
새로운 문장을 만들어 먼저 tokenize 해보았더니, 대선이라는 단어는 모델에서 '대선'으로 대응되는 것을 볼 수 있다.
모델에서 '대선'으로 정의되어 있는 것을 확인한 후 해당 단어를 vocabulary 파일에서 9311로 대응된다.
vocab의 indexing은 0부터 시작하는데 github 환경에서 line of code는 1부터 시작하는 것 때문에 9312에서 1이 뺀 값이 나오는 것이다.
즉, 앞에서 vocab 파일과 정확히 대응되는 것을 직접 눈으로 확인해볼 수 있었다.
더 나아가 토큰화된 문장을 정수 인코딩해 확인해보니 앞과 뒤의 2, 3은 padding이나 margin으로 판단할 수 있고, 역시나 9311로 인코딩된 값이 잘 쓰이고 있는 것을 확인할 수 있었다.
KoBERT 모델에서의 토큰화와 정수 인코딩
과연 그렇다면 오늘 다루고 있는 KoBERT 모델에서는 어떻게 토큰으로 나누어줄까?
!pip install --no-cache-dir transformers sentencepiece
from transformers import AutoModel, AutoTokenizer
kobert_tokenizer = AutoTokenizer.from_pretrained("skt/kobert-base-v1", use_fast=False)
kobert = AutoModel.from_pretrained("skt/kobert-base-v1")
result = kobert_tokenizer.tokenize("너는 내년 대선 때 투표할 수 있어?")
print(result)
kobert_vocab = kobert_tokenizer.get_vocab()
print(kobert_vocab.get('▁대선'))
print([kobert_tokenizer.encode(token) for token in result])
kobert 에서는 예상대로 같은 문장이 다른 방식으로 토큰화되었다.
대선이라는 단어가 '▁대선' 이란 토큰으로 대응되었고 1654 정수 값을 가진다.
문장을 모두 인코딩했을 때에도 같은 값으로 잘 인코딩되고 있음을 확인해보았다.
이 실험으로 bert 모델이 문장을 어떻게 나누어 학습할 수 있는지 이해할 수 있었다.
또한, 앞서서 설명했던 부분 중 사용하는 model과 tokenizer는 항상 mapping 관계여야 한다는 사실이 이제는 너무나 당연하게 느껴진다.
마지막으로 KoBERT가 아닌 또 다른 모델인 KcBERT를 불러와 직접 코딩해보는 과정에서 다른 모델을 적용해보는 시행착오도 미리 경험해보았다.
자! 다시 다중 분류 모델을 구현하기 위한 코드로 돌아가보자!
# Setting parameters
max_len = 64
batch_size = 64
warmup_ratio = 0.1
num_epochs = 5
max_grad_norm = 1
log_interval = 200
learning_rate = 5e-5parameter의 경우, 예시 코드에 있는 값들을 동일하게 설정해주었다.
#train & test 데이터로 나누기
from sklearn.model_selection import train_test_split
dataset_train, dataset_test = train_test_split(data_list, test_size=0.2, shuffle=True, random_state=34)사이킷런에서 제공해주는 train_test_split 메서드를 활용해 기존 data_list를 train 데이터셋과 test 데이터셋으로 나눈다. 5:1 비율로 나누었다.
tok=tokenizer.tokenize
data_train = BERTDataset(dataset_train, 0, 1, tok, vocab, max_len, True, False)
data_test = BERTDataset(dataset_test,0, 1, tok, vocab, max_len, True, False)위에서 구현한 BERTDataset 클래스를 활용해 tokenization, int encoding, padding 을 진행하였다.
train_dataloader = torch.utils.data.DataLoader(data_train, batch_size=batch_size, num_workers=5)
test_dataloader = torch.utils.data.DataLoader(data_test, batch_size=batch_size, num_workers=5)torch 형식의 dataset을 만들어주면서, 입력 데이터셋의 처리가 모두 끝났다.
6. KoBERT 모델 구현하기
class BERTClassifier(nn.Module):
def __init__(self,
bert,
hidden_size = 768,
num_classes=7, ##클래스 수 조정##
dr_rate=None,
params=None):
super(BERTClassifier, self).__init__()
self.bert = bert
self.dr_rate = dr_rate
self.classifier = nn.Linear(hidden_size , num_classes)
if dr_rate:
self.dropout = nn.Dropout(p=dr_rate)
def gen_attention_mask(self, token_ids, valid_length):
attention_mask = torch.zeros_like(token_ids)
for i, v in enumerate(valid_length):
attention_mask[i][:v] = 1
return attention_mask.float()
def forward(self, token_ids, valid_length, segment_ids):
attention_mask = self.gen_attention_mask(token_ids, valid_length)
_, pooler = self.bert(input_ids = token_ids, token_type_ids = segment_ids.long(), attention_mask = attention_mask.float().to(token_ids.device),return_dict=False)
if self.dr_rate:
out = self.dropout(pooler)
return self.classifier(out)#BERT 모델 불러오기
model = BERTClassifier(bertmodel, dr_rate=0.5).to(device)
#optimizer와 schedule 설정
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=learning_rate)
loss_fn = nn.CrossEntropyLoss() # 다중분류를 위한 대표적인 loss func
t_total = len(train_dataloader) * num_epochs
warmup_step = int(t_total * warmup_ratio)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=warmup_step, num_training_steps=t_total)
#정확도 측정을 위한 함수 정의
def calc_accuracy(X,Y):
max_vals, max_indices = torch.max(X, 1)
train_acc = (max_indices == Y).sum().data.cpu().numpy()/max_indices.size()[0]
return train_acc
train_dataloader예제 코드와 동일하게 사용하였다.
7. train
train_history=[]
test_history=[]
loss_history=[]
for e in range(num_epochs):
train_acc = 0.0
test_acc = 0.0
model.train()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm_notebook(train_dataloader)):
optimizer.zero_grad()
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
#print(label.shape,out.shape)
loss = loss_fn(out, label)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
train_acc += calc_accuracy(out, label)
if batch_id % log_interval == 0:
print("epoch {} batch id {} loss {} train acc {}".format(e+1, batch_id+1, loss.data.cpu().numpy(), train_acc / (batch_id+1)))
train_history.append(train_acc / (batch_id+1))
loss_history.append(loss.data.cpu().numpy())
print("epoch {} train acc {}".format(e+1, train_acc / (batch_id+1)))
#train_history.append(train_acc / (batch_id+1))
model.eval()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm_notebook(test_dataloader)):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
test_acc += calc_accuracy(out, label)
print("epoch {} test acc {}".format(e+1, test_acc / (batch_id+1)))
test_history.append(test_acc / (batch_id+1))KoBERT 모델을 학습시키는 코드이다. epoch의 수에 따라 학습시간이 많이 달라지는데 epoch를 5로 지정하면 30분 정도 걸린다. 앞서 이 모델에서 학습시킬 수 있도록 입력 데이터셋을 처리하고, 파라미터를 모두 지정하였으므로 예시 코드와 동일하게 진행하였다.

train dataset에 대해서는 0.979, test dataset에 대해서는 0.918의 정확도를 기록했다.
이렇게 높은 정확도를 기록하는 이유는 바로 데이터셋에 있다.
진행하고 있는 프로젝트에서 해당 프로젝트의 성격에 맞게 3만 7천 여개 정도의 데이터를 직접 재분류하고 있는데, 사람이 생각하기에는 분명히 같은 내용으로 인지되는 문장이지만 사소한 단어를 한 두개 없애서, 어떨 때는 중요한 단어를 제거해서, 짧게 잘라서, 길게 늘여뜨려서, 문장 부호를 다르게, 감탄사를 추가해서 등등 중복인 듯 중복 아닌 데이터로 학습시켰기 때문에 이렇게 높은 정확도가 나온 것이라 판단된다.
8. 직접 만든 새로운 문장으로 테스트
이제 직접 문장을 만들어 학습된 모델이 다중 분류를 잘 해내는지 알아보려고 한다.
def predict(predict_sentence):
data = [predict_sentence, '0']
dataset_another = [data]
another_test = BERTDataset(dataset_another, 0, 1, tok, vocab, max_len, True, False)
test_dataloader = torch.utils.data.DataLoader(another_test, batch_size=batch_size, num_workers=5)
model.eval()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(test_dataloader):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
test_eval=[]
for i in out:
logits=i
logits = logits.detach().cpu().numpy()
if np.argmax(logits) == 0:
test_eval.append("공포가")
elif np.argmax(logits) == 1:
test_eval.append("놀람이")
elif np.argmax(logits) == 2:
test_eval.append("분노가")
elif np.argmax(logits) == 3:
test_eval.append("슬픔이")
elif np.argmax(logits) == 4:
test_eval.append("중립이")
elif np.argmax(logits) == 5:
test_eval.append("행복이")
elif np.argmax(logits) == 6:
test_eval.append("혐오가")
print(">> 입력하신 내용에서 " + test_eval[0] + " 느껴집니다.")학습된 모델을 활용하여 다중 분류된 클래스를 출력해주는 predict 함수를 구현한 것이다.
#질문 무한반복하기! 0 입력시 종료
end = 1
while end == 1 :
sentence = input("하고싶은 말을 입력해주세요 : ")
if sentence == "0" :
break
predict(sentence)
print("\n")
5. 이 모델이 어떻게 활용될까?

이 기술은 현재 글쓴이가 진행하고 있는 캡스톤 프로젝트에서 가장 주축이 되는 기술이다.
조금 더 자세히 말하면, 사용자가 작성한 일기를 분석하여
① 어떠한 감정을 많이 표출했는지 알려주고,
② 누적된 일기들로 행복한 정도와 우울한 정도를 단계로 분류하여 정량적으로 보여주려고 한다.
① 오늘의 감정 top 3
하루동안 작성된 일기에서 어떠한 감정을 많이 표출했는지는 아래와 같이 계산할 것이다.
이 모델을 활용하여 각 문장, 즉 단발적으로 보이는 감정들을 추출할 것이다. 그리고 중립을 제외한 감정이 보이는 문장들의 퍼센트를 나누어 top3의 감정을 나타낼 것이다.
쉽게 예시를 들어보았다.
한 사용자는 20문장을 적었는데, 10 문장이 중립으로 판단되고 나머지 10문장이 중립 이외의 감정을 보였다. 10 문장 중 행복으로 판단된 문장은 5개, 분노로 판단된 문장은 4문장, 슬픔으로 판단된 문장을 1문장이었다.
→ 오늘의 대표 감정으로 행복을 추천해주고, 감정은 행복 50%, 분노 40%, 슬픔 10%으로 기록될 것이다.
② 종합 행복 지수, 종합 우울 지수
누적된 일기들로부터 행복 지수와 우울 지수를 계산하는 방법은 아래와 같다.
행복의 경우, 긍정적으로 판단되는 감정 분류 클래스가 하나 밖에 없으므로, 지난 30일동안 쓴 일기의 각 날짜 행복 퍼센트를 산술 평균 낸 값을 활용할 것이다.
우울도의 경우, 먼저 부정적으로 판단된 감정 퍼센트를 합치고 추가적으로 우울함이 묻어나는 문장에 대해서는 가중치를 더해 산술 평균을 낸 값을 활용할 것이다.
이도 쉽게 예시를 들어보았다.
지난 30일 동안 5번의 일기를 쓴 사용자가 있다.
행복이 각각의 일기에서 90%, 50%, 10%, 60%, 20% 수치로 나타났을 때,
(0.9+0.5+0.1+0.6+0.2)/5 = 0.46로 계산이 된다.
이렇게 계산된 수치를 급간으로 나누어 행복도로 보여줄 것이다.
부정적 감정은 각각의 일기에서 반대로 10%, 50%, 90%, 40%, 80% 수치로 나타났고, 추가적으로 2번째의 일기에서 "너무 우울하다"와 같이 직관적으로 "우울"이라 판단된 문장이 있었다면 각 문장 당 해당 날의 부정적 퍼센트에서 5%~10%의 가중치를 더해줄 것이다. 우울로 판단된 문장이 많아도 각 날짜의 부정적 수치는 최대 100%로 제한을 둔다.
계산 해보면, 2번째 일기에서 우울과 직접적으로 연관된 문장이 3번 나타났을 때
(0.1+(0.5+0.1*3)+0.9+0.4+0.8)/5 = 0.6으로 계산이 된다.
이렇게 계산된 수치를 급간으로 나누어 우울도로 보여줄 것이다.
6. 앞으로의 기대

우리 팀이 구상하고 있는 서비스는 일기 서비스이므로 일기에 알맞는 감정을 분류하고자 한다.
"기쁨/평온/슬픔/분노/불안/피곤" 6가지로 감정을 재분류하여 현재 이 포스팅에서 돌려본 데이터셋으로 감정을 직접 재분류하여 fine tuning 하고 있다.
결국 주어진 데이터셋이 모델의 정확도를 판가름한다. 직접 데이터셋을 재분류하고 있으므로 데이터를 조금씩 정제하여 정확도가 높아진 모습을 보여드리고자 한다.
또한, KcBERT 등 파생된 모델들이 계속 생겨나고 있는데, 더 다양한 모델에 대해서 정확도 검증을 해볼 예정이다.
'NLP' 카테고리의 다른 글
| 심리 케어 챗봇(kogpt2, kobert) 구현해 배포해보자 (4) | 2022.05.17 |
|---|